作者:郑小斌-杭州 | 来源:互联网 | 2023-09-17 22:33
篇首语:本文由编程笔记#小编为大家整理,主要介绍了使用新的物理模拟引擎加速强化学习相关的知识,希望对你有一定的参考价值。强化学习(RL)是一种流行的教学机器人导航和操纵
篇首语:本文由编程笔记#小编为大家整理,主要介绍了使用新的物理模拟引擎加速强化学习相关的知识,希望对你有一定的参考价值。
强化学习(RL) 是一种流行的教学机器人导航和操纵物理世界的方法,其本身可以简化并表示为刚体之间的交互1(即,当对它们施加力时不会变形的固体物理对象)。为了便于在实际时间内收集训练数据,RL 通常利用模拟,其中任意数量的复杂对象的近似值由许多由关节连接并由执行器提供动力的刚体组成。但这带来了一个挑战:RL 代理通常需要数百万到数十亿的模拟帧才能精通简单的任务,例如步行、使用工具或组装玩具积木。
虽然通过回收模拟帧在提高训练效率方面取得了进展,但一些 RL 工具通过将模拟帧的生成分布到许多模拟器来回避这个问题。这些分布式模拟平台产生了令人印象深刻的结果,训练速度非常快,但它们必须在具有数千个 CPU 或 GPU 的计算集群上运行,而大多数研究人员无法访问这些集群。
在“ Brax - 用于大规模刚体仿真的可微分物理引擎”中,我们展示了一种新的物理仿真引擎,它与仅具有单个 TPU 或 GPU 的大型计算集群的性能相匹配。该引擎旨在在单个加速器上高效运行数千个并行物理模拟以及机器学习 (ML) 算法,并在互连加速器的 pod 中无缝扩展数百万个模拟。我们已经开源了引擎以及参考 RL 算法和模拟环境,这些都可以通过Colab访问。使用这个新平台,我们展示了比传统工作站设置快 100-1000 倍的培训。
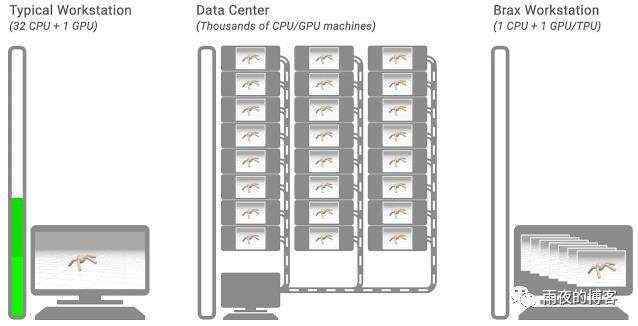
物理仿真引擎设计机会
刚体物理用于视频游戏、机器人、分子动力学、生物力学、图形和动画以及其他领域。为了对此类系统进行准确建模,模拟器集成了来自重力、电机驱动、关节约束、物体碰撞等的力,以模拟物理系统随时间的运动。
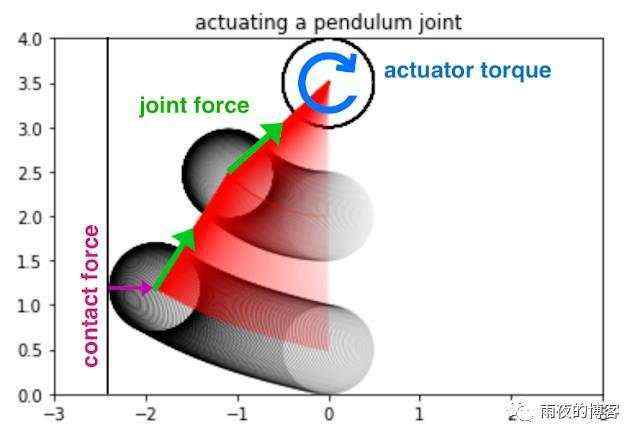
仔细研究当今大多数物理模拟引擎的设计方式,有一些提高效率的巨大机会。正如我们上面提到的,典型的机器人学习管道将单个学习器置于紧密反馈中,同时进行许多模拟,但在分析此架构后,人们发现:
这种布局带来了巨大的延迟瓶颈。由于数据必须通过数据中心内的网络传输,因此学习者必须等待 10,000 多纳秒才能从模拟器中获取经验。如果这种体验已经与学习者的神经网络在同一设备上,延迟将降至 <1 纳秒。
训练代理所需的计算(一个模拟步骤,然后更新代理的神经网络)被打包数据(即,在引擎内编组数据,然后转换为诸如protobuf 之类的有线格式,然后进入TCP缓冲区,然后在学习者端撤消所有这些步骤)。
每个模拟器中发生的计算非常相似,但并不完全相同。
Brax 设计
针对这些观察结果,Brax 的设计使其物理计算在其数千个并行环境中的每一个环境中完全相同,方法是确保模拟没有分支(即,模拟“ if”逻辑因此而发散环境状态)。物理引擎中分支的一个示例是在球和墙壁之间施加接触力:将根据球是否接触墙壁执行不同的代码路径。也就是说,如果球接触墙壁,则将执行用于模拟球从墙壁反弹的单独代码。Brax 混合使用以下三种策略来避免分支:
用连续函数替换离散分支逻辑,例如使用带符号距离函数近似球壁接触力。这种方法会带来最大的效率收益。
在 JAX 的实时编译期间评估分支。许多基于环境静态属性的分支,例如两个对象是否可能发生碰撞,可以在模拟时间之前进行评估。
在模拟过程中运行分支的两侧,然后只选择所需的结果。因为这样会执行一些最终没有用到的代码,所以与上面相比,浪费了一些操作。
一旦保证计算完全一致,就可以降低整个训练架构的复杂性,以便在单个 TPU 或 GPU 上执行。这样做可以消除跨机器通信的计算开销和延迟。在实践中,这些变化将可比工作负载的训练成本降低了 100 到 1000 倍。
Brax 环境
环境是微小的封装世界,定义了 RL 代理要学习的任务。环境不仅包含模拟世界的手段,还包含功能,例如如何观察世界以及在该世界中定义目标。
近年来出现了一些标准基准环境,用于测试新的 RL 算法并使用研究科学家普遍理解的指标评估这些算法的影响。Brax 包括来自流行的OpenAI 健身房的 四个此类即用型环境:Ant、HalfCheetah、Humanoid和Reacher。

Brax 还包括三种新颖的环境:物体的灵巧操纵(机器人技术中的一个流行挑战)、广义运动(一种代理前往放置在其周围任何位置的目标)以及工业机器人手臂的模拟。

性能基准
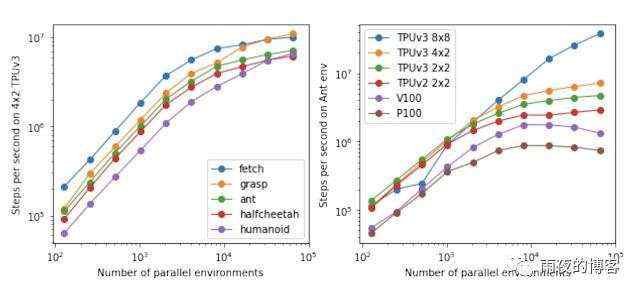
分析 Brax 性能的第一步是测量它模拟大批量环境的速度,因为这是要克服的关键瓶颈,以便学习者消耗足够的经验来快速学习。
下面的这两个图显示了 Brax 可以产生多少物理步骤(环境状态的更新),因为它的任务是并行模拟越来越多的环境。左图显示,Brax 将每秒步数与并行环境的数量成线性比例,仅在 10,000 个环境时遇到内存带宽瓶颈,这不仅足以训练单个智能体,还适用于训练整个群体代理商。右图显示了两件事:第一,Brax 不仅在 TPU 上表现良好,而且在高端 GPU 上也表现良好(参见V100和P100曲线),第二,通过利用 JAX 的设备并行原语, Brax 在多个设备之间无缝扩展,每秒达到数亿个物理步骤(参见TPUv3 8x8曲线,即 64 个TPUv3芯片通过高速互连直接相互连接)。
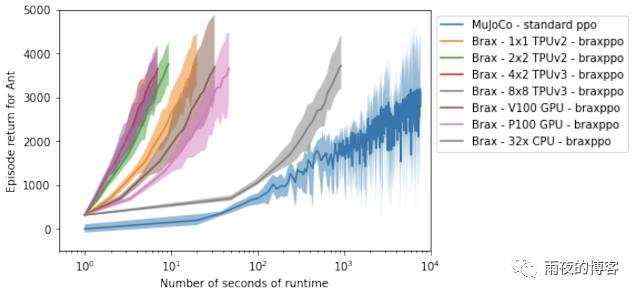
分析 Brax 性能的另一种方法是衡量其对在单个工作站上运行强化学习实验所需时间的影响。在这里,我们将 Brax 训练流行的Ant基准环境与其OpenAI 对应物进行比较,后者由MuJoCo 物理引擎提供支持。
在下图中,蓝线代表标准工作站设置,其中学习器在 GPU 上运行,模拟器在 CPU 上运行。我们看到训练蚂蚁以合理的熟练度(y 轴上的 4000 分)运行所需的时间从蓝线的大约 3 小时下降到在加速器硬件上使用 Brax 的大约 10 秒。有趣的是,即使仅在 CPU 上(灰线),Brax 的执行速度也快了一个数量级,这得益于处于同一进程中的学习器和模拟器。
Physics Fidelity
设计一个与现实世界的行为相匹配的模拟器是一个已知的难题,这项工作没有解决。尽管如此,将 Brax 与参考模拟器进行比较以确保它产生的输出至少同样有效是有用的。在这种情况下,我们再次将 Brax 与MuJoCo进行比较,后者因其模拟质量而广受好评。我们希望看到,在其他条件相同的情况下,无论是在 MuJoCo 还是 Brax 中训练,策略都具有相似的奖励轨迹。
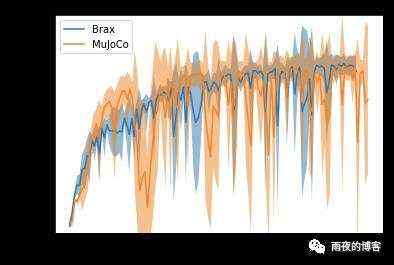
这些曲线表明,随着两个模拟器的奖励以大致相同的速度增长,两个引擎计算物理的复杂性或解决难度相当。由于两条曲线都以大致相同的奖励达到顶峰,因此我们相信相同的一般物理限制适用于在任一模拟中尽其所能操作的代理。
我们还可以测量 Brax 保持线性动量、角动量和能量守恒的能力。
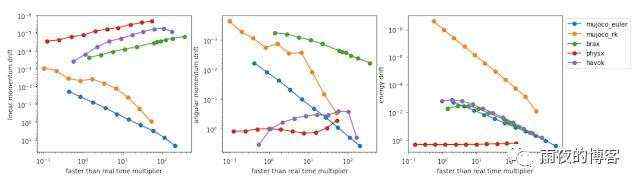
MuJoCo 的作者 首先提出了这种物理模拟质量的衡量标准,以了解模拟如何在计算越来越大的时间步长时偏离轨道。在这里,Brax 的表现与其邻居相似。
结论
我们邀请研究人员通过在Brax Training Colab 中训练他们自己的策略来对 Brax 的物理保真度进行更定性的测量。学习到的轨迹与 OpenAI Gym 中看到的轨迹非常相似。










 京公网安备 11010802041100号
京公网安备 11010802041100号